
作者 | AIming 编辑 | 自动驾驶Daily原文链接:https://www.zhihu.com/question/678583188/answer/1907132729197323201
去年业界朋友交流的时候就被VLA这个概念吸引到了,最近无论是具身智能还是自动驾驶都出现了大量的VLA相关的研究进展,有一种莫名的直觉,这种范式很可能会改变自动驾驶业界的玩法,那么正好借着Waymo的EMMA工作,来和大家学习交流下VLA这种范式。
作者 | AIming 编辑 | 自动驾驶Daily原文链接:https://www.zhihu.com/question/678583188/answer/1907132729197323201
去年业界朋友交流的时候就被VLA这个概念吸引到了,最近无论是具身智能还是自动驾驶都出现了大量的VLA相关的研究进展,有一种莫名的直觉,这种范式很可能会改变自动驾驶业界的玩法,那么正好借着Waymo的EMMA工作,来和大家学习交流下VLA这种范式。
VLA概念及背景介绍
视觉-语言-动作模型(Vision-Language-Action, VLA),通过整合视觉、语言和行为信息的互联网规模数据集,使机器人不仅能够识别和描述其环境,还能够根据上下文进行推理并在复杂、动态的环境中执行适当的动作。VLA强调一体化多模态端到端架构,非感知规控的模块化方案,标志着智能具身(Embodied AI)重要发展的里程碑。
因此VLA并非自动驾驶原生技术,其本质是机器人领域技术范式的跨界延伸
众所周知,自动驾驶的模型大家都在往感知决策一体化来推进,感觉整体都可以说成是VLA以及某种变体(本质上都是端到端了),总结以下有三个路径:
另外还有一些非VLA范式,是结合了VLM的工作:比如VLM仅用决策,和下游解耦合串并联。
代表工作:地平线的SENNA、AlphaDrive ,理想DriveVLM
当然具身智能也有不同的VLA探索架构形式,类似Physical Intelligence 的pi0 , VLM+(diffusion policy/flow matching)的VLA形式或者是智元GO1的Vision-Language-Latent-Action(ViLLA)架构,采用隐式空间进行特征对齐增强来获得更好的动作。本文暂不开展具身智能领域VLA,重点关注自动驾驶语境下的VLA范式。
以往的自动驾驶系统模块化设计,虽然这种设计有助于更轻松地调试和优化单个模块,但具有模块之间的累积错误和模块间通信延迟等问题。
FSDV12/13产品化已经证明端到端成为一种优秀的方案,直接学习从传感器数据中生成驾驶动作。这种方法消除了模块之间对接口的需求,并允许从原始传感器到轨迹控制的端到端优化。
基于以上背景,我认为VLA更是一种端到端的架构升级,当然是否需要Language部分,以及Language是以特征还是常识还是COT等方式注入,业界还处于探索阶段。特斯拉也并没有宣传使用L部分,更多的还是VA(vision-action)的范式。以下一个图标来描述模型的优劣
| 多模态大模型(VLM/MLLM) | 端到端模型(E2E/VA) | VLA模型 |
精准3D感知 | ❌ | ✅ | ✅ |
精准数值预测 | ❌ | ✅ | ✅ |
常识理解 | ✅ | ❌ | ✅ |
逻辑思维 | ✅ | ❌ | ✅ |
可解释性 | ✅ | ❌ | ✅ |
EMMA
原文链接:
https://arxiv.org/abs/2410.23262arxiv.org/abs/2410.23262
EMMA,这是一种由 Gemini 提供支持的端到端多模态自动驾驶模型。它将 Gemini 视为核心组件,并将自动驾驶任务重新构建为视觉问答问题,以适应 MLLM 的范式,旨在最大限度地利用 Gemini 的世界知识和配备思维链(COT)工具的推理能力。与传统模块化方案不同,EMMA 直接将原始摄像头传感器数据映射到各种特定于驾驶的输出,包括规划轨迹、感知目标和道路图估计。所有任务输出都表示为纯文本,因此可以通过特定任务的提示在统一的语言空间中联合处理。
Motivation:
如何利用MLLM海量的知识辅助自动驾驶任务,解决长尾特殊场景?思考以下几个case:
目前来说其实自动驾驶大部分问题,还可以分类为感知系统不完备(感知背下了一切的锅)
感知系统的不完备导致自动驾驶的场景泛化困难,虽然已有的3D 动态E2E /Online mapping /Occ /红绿灯等感知模块已经尽可能获取完备的感知,但是目前的感知系统仍然不好处理上述的长尾场景,有没有一种可能存在一种较为完备的系统,比较优雅的处理上述的长尾场景(先叠个甲,大部分简单驾驶场景完全没必要用VLA这种范式,但是这里VLA看起来一种能通用解决的思路)
因此大算力、大模型的背景下,尝试使用MLLM可以作为一个潜在的解决方案
模型架构图
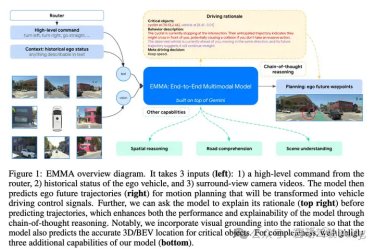
模型总体架构
输入:
输出:
均表达为文本格式,自回归的方式预测n个token
1. 核心输出:未来5s轨迹,BEV(鸟瞰图)位置 (x, y)
轨迹两种表达形式:
本文这里采用文本转浮点数的表达形式。
2.可选输出:
核心组件:Gemini 1.0 Nano-1
这个多模态大模型是非开源的,知乎有其他大佬解读,大家可以移步:段淇源:解读 Gemini 技术报告(Gemini: A Family of Highly Capable Multimodal Models)
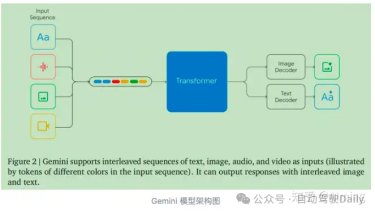
大概总结几点:
这样的大模型具备两个特点:
(1) 在庞大的互联网规模数据集上接受训练,这些数据集提供了超出常见驾驶日志所包含的丰富“世界知识”(2) 通过思维链推理等技术展示了卓越的推理能力, 但这在自动驾驶系统由于效率问题几乎不可用。因此也需要探索一种结合cot方式的自动驾驶VLA模型
能力一:End-to-End Motion Planning
通过上述的Gemini模型,也可以做端到端规划,具体来说
(1) 使用导航系统(例如谷歌地图)进行路线规划和意图确定
(2) 利用过去的行为来确保随着时间的推移平稳、一致地驾驶。
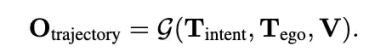
那么就是输入1,2表示的文本,和环视视频,输出对应的轨迹。
那么这样的公式,很容易构建真值,需要导航意图-历史轨迹-未来轨迹-视频数据,这四个元素,那么就可以给Gemini大模型进行监督微调(Supervised Fine-Tuning, SFT)
这样也无需高精地图,仅使用来自 Google Maps 的导航信息。
这里是利用 2 秒的历史轨迹来预测未来 5 秒的轨迹。
能力二:Planning with Chain-of-Thought Reasoning
将思维链推理纳入端到端规划器轨迹生成中,这里要求模型在预测最终未来轨迹航点 trajectory 的同时阐明其驾驶决策理由 。
因此这种VLA模型不仅具备端到端planning的能力,还可以通过思维链推理来提高轨迹推理能力,利用输出驾驶原因来具备一定的可解释性。
从 4 种类型的粗粒度信息发展到细粒度信息
R1 - 场景描述:大致描述驾驶场景,包括天气、日期、交通状况和道路状况。例如:天气晴朗,阳光明媚,现在是白天。这条路是四车道的无分隔街道,中间有一条人行横道。街道两旁停着汽车。
R2 - 关键目标:是可能影响自主车辆驾驶行为的道路agent,我们要求模型识别其精确的 3D/BEV 坐标。例如:行人为 [9.01, 3.22],车辆为 [11.58, 0.35]。
R3 - 关键目标的行为描述 描述已识别关键目标的当前状态和意图。具体示例如下:行人目前站在人行道上,望向道路,可能正准备过马路。这辆车目前在我前面,朝着同一个方向行驶,它的未来轨迹表明它将继续直行。
R4 - 原始驾驶行为决策:包括 12 类高级驾驶决策,总结了给定先前观察的驾驶计划。“I should keep my current low speed.”
关键目标的3D/BEV信息的标注可以通过现有的3D 感知模型来预刷,(这就不得不提到我们之前在图森实习做的离线3D检测跟踪器,CTRL方案 原文链接:Once Detected, Never Lost: Surpassing Human Performance in Offline LiDAR based 3D Object Detection)
关键目标的行为描述,可以通过预测模块来获得。
那么在训练和推理期间,该模型在预测未来的waypoints之前预测驾驶决策理由的所有四个组成部分(R1-R4)
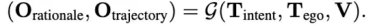
注意这里是可选的,驾驶决策理由肯定会带来大量的token消耗,造成推理效率低下
能力三:EMMA Generalist(通才网络)
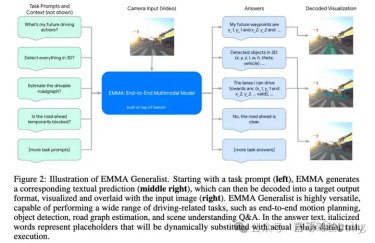
图中绿色部分都是用来微调的task prompts和context信息,最终回答就如蓝色框所示,里面的信息可以可视化成polyline、3D box,自车轨迹等
虽然端到端运动规划是最终的核心任务,但全面的自动驾驶系统需要额外的功能。也就是感知 3D 世界并识别周围的物体、驾驶引导线预测(Road graph estimation)和交通状况。 EMMA 构建为一个通才模型,能够通过训练混合物处理多个驾驶任务。
采用指令调优(instrunction tuning, IT),这是 LLM 中一种常用调优方法。
关于指令调优知乎上也有一些学习资料
输入 Task prompts 中包含的特定任务提示一起联合训练所有任务。具体的任务分为三个主要类别:空间推理、驾驶引导线预测(Road graph estimation)和交通场景理解。当然这种形式感觉很灵活,可以继续拓展不同的任务。
空间推理:
其实就是3D 目标检测的文本形式,这里遵循 Pix2Seq ,并将输出的 3D 边界框表述为 OboxesO_{boxes }O_{boxes } = set{text(x, y, z, l, w, h, θ, cls)},其中 (x, y, z) 是车辆中心位置,l、w、h 是框的长度、宽度和高度,θ 是航向角,cls 是文本中的类标签。
通过编写具有两位小数的浮点数将 7D 框转换为文本,每个维度之间用空格分隔。然后使用固定的 prompt: 表示检测任务,例如 “detect every object in 3D”,然后输出对应的box(文本形式),如下公式所示:
驾驶引导线预测(Road graph estimation):
这里如果用Road graph estimation,我一开始还以为是online mapping那种任务,但其实是类似道路可驾驶的中心线的概念。
输出包括语义元素(例如车道标记、标志)和物理属性(例如车道曲率)。这些 road 元素的集合形成了一个 road graph。例如,车道段由 (a) 节点表示,其中车道遇到交叉、合并或拆分,以及 (b) 这些节点之间沿交通方向的边缘。完整的 road-graph 由许多这样的polyline组成
虽然每条polyline内的边都是定向的,但每条polyline不一定相对于其他元素具有唯一的顺序。这与目标检测类似,其中每个框都由有序属性(左上角、右下角)定义,但框之间的相对顺序不一定存在。有几项现有工作使用 Transformer 对polyline进行建模与语言模型有类似的地方。

交通场景理解:
任务测试模型对整个场景上下文的理解。例如,由于施工、紧急情况或其他事件,道路可能会暂时阻塞。及时检测这些障碍物并安全地绕过它们;但是,场景中需要多个提示来确定是否存在阻塞。使用以下公式关注模型如何执行此临时阻塞检测任务:
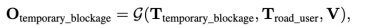
其中Otemporary-blockage是指示潜在障碍物的模型输出,答案就是“是”/“否
Troad-user表示前方道路上的所有物体
Ttemporary-blockage是文本提示“前方道路是否暂时被阻塞? "
实验部分(重点部分):
其实上述的指令调优,任务定义方式都是比较简单也好理解。重点看一下这里的实验结果,表露出来了什么信息。
端到端规划 waymo open datasets数据集实验:
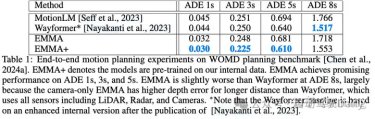
waymo在自己家的数据集刷了一遍,EMMA+对比EMMA其实就是预训练用了waymo内部数据集。这里wayformer之前是一个agent运动预测模型,这里修改成了用于预测自车未来轨迹的模型。
ADE就是平均距离误差的指标,当然是越小越好。
端到端轨迹采样数量实验:
在推理过程中,从多个候选轨迹中对最终轨迹进行采样对最终性能很关键。MotionLM 和 Wayformer 都生成了 192 个候选轨迹,随后使用 k-means 聚类将其聚合为 6 个cluster,从而产生 6 个代表性轨迹。最终轨迹是根据它们的相关概率从这 6 个代表性轨迹中选择的。
为了公平起见,我们还使用 Top-K 解码策略对多个轨迹进行采样,最高可达 K = 24。然后,我们计算所有轨迹之间的成对 L2 距离,并选择平均 L2 距离最低的轨迹作为最终预测轨迹,它可以被视为所有预测中的 “中位数 ”轨迹。
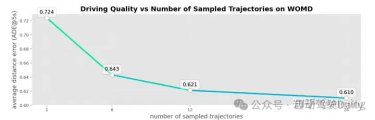
可以看见在wod数据集上还是轨迹越多越好,但边际效益递减,即增加候选轨迹数量的优势在某个点之后会减弱。
端到端规划nuScenes实验:
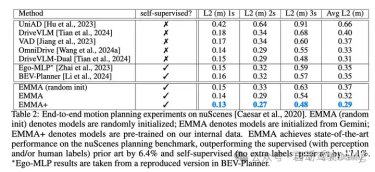
这里有个值得关注的点,与 Waymo数据集不同,在nuScenes对多个轨迹进行采样并没有产生明显的改进。这里推测是由于 nuScenes 在更简单的驾驶场景中的预测时间范围 (3s) 较短。因此只用top1 预测就够了
端到端规划的 COT实验:

ablation里面思维链对最终e2e planning的影响,看起来是否添加R1的scene description对最终规划没有什么用,但是其他三个部分是有用的。
端到端规划的Scaling实验:
如图 4 所示。在更大的训练集上训练模型时,会在过拟合之前观察到较低的 eval 困惑度。
结果表明,即使使用当前的大规模数据集,EMMA 的驾驶质量也尚未趋于稳定
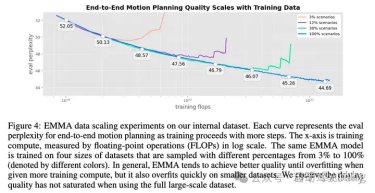
在内部数据集上的 EMMA 数据scaling实验。每条曲线都表示随着训练步骤的增加,端到端运动规划的 eval 困惑度。x 轴是训练计算,由对数刻度的浮点运算 (FLOP)(大模型scaling law中常用的度量指标), 相同的 EMMA 模型在四种大小的数据集上进行训练,这些数据集以从 3% 到 100% 的不同百分比
一般来说,当给予更多的训练计算时,EMMA 往往会获得更好的质量,直到过拟合,但它也会在较小的数据集上快速过拟合。但观察到,在使用完整的大规模数据集时,轨迹质量也未饱和。
这里就很值得关注了,意味着10^ 21次方的flop计算迭代仍不能收敛,还需要多少计算资源未知,这个玩法在waymo这种资源的公司,都没有探索明确出来多少训练资源能收敛.....
所以如何在越大的模型 + 越多的数据 + 越多的训练轮数上面进行拓展还有很多可探索的工作,而且低成本的训练方案也至关重要。
3D Object Detection实验:
由于EMMA输出的检测框,没有置信度分数,因此直接比较精度/召回率,可以看见EMMA+的检测性能看起来还好,当然比较的都是一些很早期的3D检测器,个人猜测,VLA这种面向规划模型,3D感知性能有个大概还行的样子就够了

驾驶引导线预测(Road graph estimation)实验
用于预测一组无序的折线,每条折线都表示为一系列waypoints。用两个指标来衡量道路图预测的质量:
(1) 车道级精度和召回率,当且仅当它们的chamfer distance 在 1 米以内时,我们定义预测的车道折线和真实车道折线之间的真正正匹配;
(2) 像素级精度和召回率,其中折线被栅格化为分辨率为 1 米的 BEV 网格——然后我们将 BEV 网格视为图像,并根据每个像素的匹配计算精度和召回率。
此任务涉及多种设计选择。
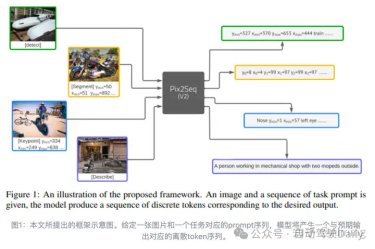
pix2seq任务输入输出
以上的关键设计进行对应ablation:
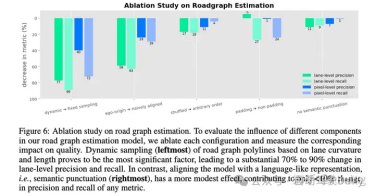
图 6 各种设计选择的消融研究
从最佳设计开始,系统地消融以下每一种配置,并评估由此产生的质量下降。
这里并没有具体量化具体的指标参数,如ADE之类的,更多的还是这种指标下降的百分比的比较,也是论文写作的一种表现手法,看的更直观。
首先第一个部分:基于车道曲率和长度的道路图折线动态采样(最左侧)被证明是最重要的因素,导致车道级精度和召回率发生 70% 到 90% 的大幅变化。相比之下,将模型与类似语言的表示形式对齐,即语义标点符号(最右侧),效果变化不大,对任何指标的精度和召回率仅产生 <10% 的变化。
具体来解释每一部分(这里细节比较多,感觉花了很大精力来做这个任务的):
Scene Understanding实验
针对临时堵塞的场景理解任务研究,这里并没有展开其他的复杂交通场景,应该可以加更多其他特殊场景。
如图7所示,有三种比较方案:

第一个实验:相当于是直接FT,效果就不错。
第二个实验:和驾驶线估计的任务联合FT,会掉指标(典型多任务打架)
第三个实验:先短暂预训练驾驶线预测任务,然后联合两个任务FT,指标正常了
第四个实验:先较长时间的预训练驾驶线预测任务,然后联合两个任务FT,指标更好了。多任务上的不同训练策略很重要,这种大家平常训练多任务感知模型的时候也会遇见(多任务打架)。
指令调优联合训练实验:

从三个任务来看:端到端规划、3D 目标检测、驾驶引导线预测。 所有三项任务的联合训练产生了较显著的改进,通才模型的性能比单任务模型高出 5.5%。
其中,当共同训练两项任务时,某些组合会比其他组合带来更大的收益。例如,当与planning相结合时,检测性能的提升最大,而驾驶引导线预测在与planning相结合时同样受益最大,但是plannning的指标掉了,估计是因为驾驶引导线某种程度也很类似planning的轨迹,导致模型的一些confused。
但总体来说, 可以看到任务的互补性。例如,当模型可以准确识别车辆的位置时,道路图估计会变得更加容易。同样,驾驶质量与理解目标的交互密切相关,3D 目标检测增强了这项技能。
这些发现表明,追求通才模型是未来研究的一个有前途的方向,有可能更深入地了解任务协同和性能优化。
可视化验证:
这里就重点放一些有意思的可视化,更多大家可以去原文看
三个图从左到右分别是planning结果(轨迹横向扩张了大概车宽的距离)、3D detection 、 驾驶引导线

垃圾袋避让

梯子避让,其实做occ的同学应该知道,这类稀疏带空的低矮目标真值也挺难构建的

小松鼠刹停,这种近距离小目标,如果occ如果做的好,也可以预测出来,但是如果是mllm的形式思维链推理也包含准确的松鼠信息,那这个能力还是挺牛逼的

白色的狗 刹停,还是一个比较复杂的路口,驾驶引导线的预测看起来也没有特别大问题。

道路表示为左变道,但是左侧有施工牌,这个planning就考虑这些复杂信息,直接沿着当前车道开

道路避障的场景

交警避让

黄灯 刹停 ,可见大量的常识信息包含了这些交通知识
存在的问题和未来的解决方案:
内存和视频帧数问题:目前,模型仅处理有限数量的帧(最多 4 帧),这限制了其捕获驾驶任务所必需的长时空依赖关系的能力。有效的驾驶不仅需要实时决策,还需要在更长的时间范围内进行推理,依靠长期记忆来预测和响应不断变化的场景。增强模型执行长期推理的能力是未来研究的一个有前途的领域。这可以通过集成内存模块或扩展其有效处理较长视频序列的能力来实现,从而实现更全面的时间理解。
扩展到 LiDAR 和雷达输入:(waymo车上有很多lidar,但是这个模型明显没有利用到这些信息)由于无法将摄像头输入与 LiDAR 或雷达融合,因此 3D 空间推理受到限制 。严重依赖于预先训练的 MLLM,这些 MLLM 通常不包含 LiDAR 或雷达输入。集成这些 3D 传感模式会面临两个关键挑战:1) 可用相机和 3D 传感数据量之间存在显着不平衡,导致与基于相机的编码器相比,3D 传感编码器的通用性较差。2) 3D 传感编码器的发展尚未达到基于摄像头的编码器的规模和复杂性。应对这些挑战的一个潜在解决方案是使用与相机输入仔细对齐的数据来预训练大型 3D 传感编码器。这种方法可以促进更好的跨模态协同,并显著提高 3D 传感编码器的泛化能力。
规划轨迹的验证:模型可以直接预测驾驶轨迹,而无需依赖中间输出。增加额外的数据,会有实时性和可解释验证的矛盾。通才模型也可以联合预测额外的人类可读输出,例如目标和驾驶引导线,并且驾驶决策可以用思维链驾驶原理进一步解释。但不能保证这些输出100%一致的(大模型推理过程错了,但结果对了情况也是有的)。此外,额外的输出会为部署带来巨大的运行时延迟开销。
用于闭环评估的传感器仿真:大家也都知道开环评估不靠谱。与闭环性能没有很强的相关性。所以为了在闭环环境中准确评估端到端自动驾驶系统,需要一个全面的传感器仿真解决方案。然而,传感器仿真的计算成本通常比行为仿真器高(如苹果的GIGAFLOW)。除非进行实质性优化,否则这种巨大的成本负担可能会阻碍端到端模型的全面测试和验证。
这里给没有做过仿真的同学科普一下:
一段式端到端: 一般需要传感器的闭环仿真,这里推荐一下 乃岩老师在图森的开展闭环仿真工作(基于神经渲染的下一代真实感仿真)Naiyan Wang:基于神经渲染的下一代真实感仿真 ,这里实习的时候也有幸在mentor闫岩的指导下优化了里面的部分模块。当时在图森参与的是传感器的联合仿真:也就是图像+点云的传感器仿真。当然现在有很多拿3D GS来进行图像仿真部分。二段式端到端 :一般就是行为仿真,只需要模拟感知的一些结构化信息(车道线、感知目标、红绿灯等信息),比如苹果GIGAFLOW、地平线的GUMP。这样的仿真成本更低,一般可以用于二阶段端到端的闭环仿真、强化学习来使用。
当然还有一些生成类的工作可以实现类似的事情,比如地平线的UMGen工作:半闲:CVPR 2025 | UMGen:多模态驾驶场景生成统一框架 ,也是超哥带领的地平线World model项目中的收尾工作~
车载部署的挑战:自动驾驶需要实时决策,这在部署大型模型时构成了重大挑战,因为它们的推理延迟会增加。这就需要优化模型或将其提炼成适合部署的更紧凑形式,同时保持性能和安全标准,相对于传统模型,计算要求更高。在模型大小、效率和质量之间实现这种微妙的平衡。
总结
EMMA利用MLLA实现了端到端planning的方案,并且通过额外的COT输出,具备了一定的可解释性,让端到端不再是黑盒模型。这种方案也属于自动驾驶VLA领域的初期探索工作,后续可发展可探索空间也有很多,还有一些工作比如OpenEMMA,LightEMMA这些,后续计划进一步学习这些内容,以文章的形式发出来
个人认为,自动驾驶应该会出现于自动驾驶的用于车端平台的垂域大模型,也可能并不需要L部分,如果高效率在车端芯片上推理,综合来看特斯拉FSDV13很接近这种形态。
*以上内容来源于自动驾驶Daily